Kubernetes Workloads (Deployments, Jobs, CronJobs, etc.)

Hi! My name is Safia Khatoon. I am complete my Bachelors in Technology from RTC Institute Of Technology. My specialisation in Computer Science and Engineering.I love contributing to Open Source with the help of the skills I gain.
Also, I'm working on my YouTube Channel as well where I teach about DevOps tools and make technical content. You can have a look at it through my profile.
Feel free to reach out to me! I'd be happy to connect with you.
Kubernetes Workloads:
Kubernetes workloads refer to the set of resources that define how your application runs on a Kubernetes cluster. These resources include deployments, stateful sets, daemon sets, and jobs.
Deployments :
✨ Deployments are used to manage stateless applications, such as web servers, and ensure that a specified number of replicas are always available and running.
Create a new file using the vim editor

In this example, the
apiVersionandkindfields specify that this is a Kubernetes deployment file for version 1 of theappsAPI and aDeploymentresource type, respectively. Themetadatasection includes a name and label for the deployment. Thespecsection specifies the desired number of replicas (3 in this case), a selector for the deployment, and a template for the pods that will be created. Thetemplatesection specifies the metadata and specification for the container(s) to be deployed, including the image to be used, the ports to expose, and any environment variables to set.sudo snap install kubectl --classickubectl apply -f deployment.ymlkubectl get pods

Statefulsets :
Statefulsets are used to manage stateful applications, such as databases, and provide stable network identities and stable storage.
Create a new file using the vim editor.


kubectl apply -f statefulset.yml

In this example, the apiVersion and kind fields specify that this is a Kubernetes StatefulSet file for version 1 of the apps API and a StatefulSet resource type, respectively. The metadata section includes a name for the StatefulSet. The spec section specifies the desired number of replicas (3 in this case), a selector for the StatefulSet, and a template for the pods that will be created. The template section specifies the metadata and specification for the container(s) to be deployed, including the image to be used, the ports to expose, and any volume mounts to be created. The volumeClaimTemplates section specifies the metadata and specification for the persistent volume claims that will be created for each pod. In this example, a single ReadWriteOnce access mode PVC (persistent volume claim) with a capacity of 1Gi and storage class name "my-db-storage" is created, and each pod will mount this volume to the path /data/db. The serviceName field is used to create a stable network identity for each pod in the StatefulSet.
Daemonsets:
- Create a new file using the vim editor.
Daemonsets are used to ensure that a specific pod is running on each node in a Kubernetes cluster, typically used for logging or monitoring.
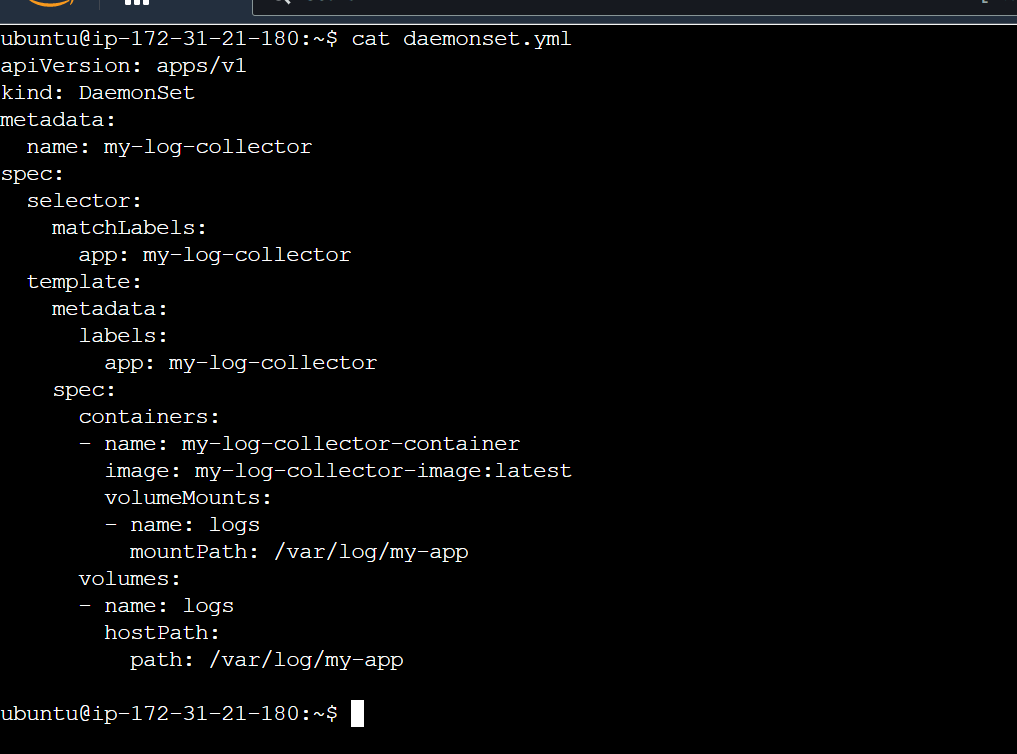
kubectl apply -f daemonset.yml

In this example, the apiVersion and kind fields specify that this is a Kubernetes DaemonSet file for version 1 of the apps API and a DaemonSet resource type, respectively. The metadata section includes a name for the DaemonSet. The spec section specifies a selector for the DaemonSet and a template for the pods that will be created. The template section specifies the metadata and specification for the container(s) to be deployed, including the image to be used, and any volume mounts to be created. The volumes section specifies the hostPath volume to be mounted on the host for each pod, in this example at the path /var/log/my-app. This will ensure that the logs for the my-app application are collected from every node in the Kubernetes cluster. The matchLabels field in the selector section ensures that the DaemonSet will only be deployed to nodes with the app: my-log-collector label.
Jobs :
Jobs are used to perform batch processing tasks, such as data processing or backups, and ensure that the job completes successfully before terminating the pod.
Create a new file using the vim editor.

In this example, the apiVersion and kind fields specify that this is a Kubernetes Job file for version 1 of the batch API and a Job resource type, respectively. The metadata section includes a name for the Job. The spec section specifies a template for the pods that will be created, including the metadata and specification for the container(s) to be deployed, and the command and arguments to be run within the container. In this example, the command executed within the container is echo "Hello, World!". The restartPolicy field is set to Never, which means that the container will not be restarted if it fails to complete. The backoffLimit field is set to 2, which means that the Job will retry up to two times in case of failure.
Once the Job is created, Kubernetes will create a single pod to run the specified command, and ensure that the pod runs to completion. If the pod fails to complete successfully, the Job will retry according to the backoffLimit. Once the pod completes successfully, the Job is considered complete, and the pod is deleted.

Kubernetes CronJob:
A Kubernetes CronJob is a controller object that creates Jobs on a predefined schedule, similar to the cron utility in Linux. CronJobs are commonly used to run scheduled or periodic tasks, such as backups, database maintenance, or data processing.
- Create a new file using the vim editor.
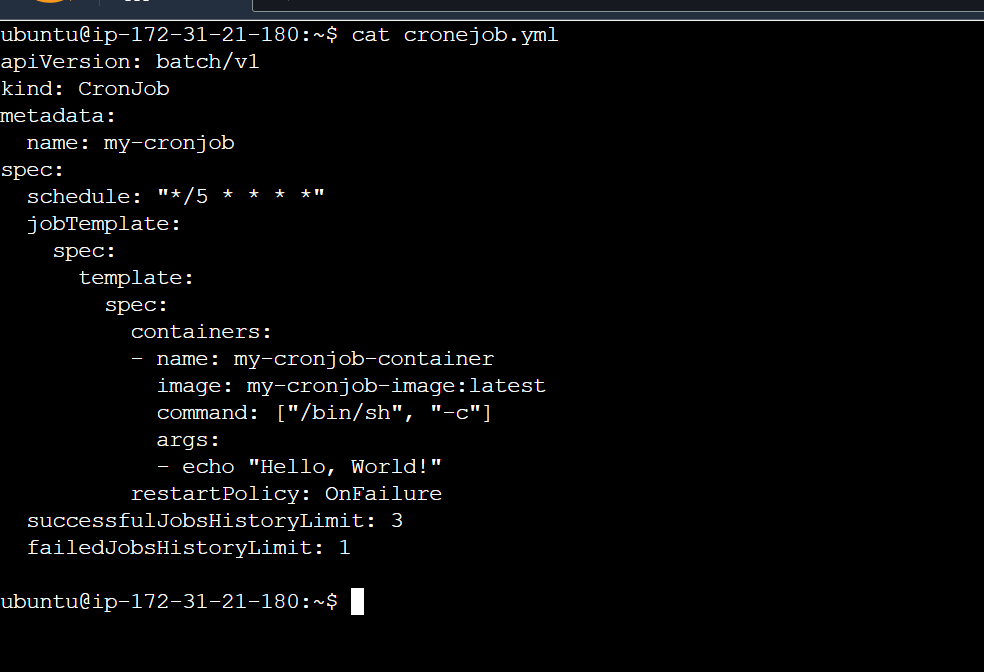

In this example, the apiVersion and kind fields specify that this is a Kubernetes CronJob file for version 1 of the batch API and a CronJob resource type, respectively. The metadata section includes a name for the CronJob. The spec section specifies the schedule for the CronJob using the standard cron format (*/5 * * * * means "every 5 minutes"), and the template for the Jobs that will be created. The jobTemplate section specifies the metadata and specification for the container(s) to be deployed, and the command and arguments to be run within the container. In this example, the command executed within the container is echo "Hello, World!". The restartPolicy field is set to OnFailure, which means that the container will be restarted if it fails to complete. The successfulJobsHistoryLimit and failedJobsHistoryLimit fields specify the number of successful and failed jobs to keep in the job history, respectively.
Once the CronJob is created, Kubernetes will create a new Job on the specified schedule. The Job will run the specified command within a container, and if it completes successfully, the Job is considered complete, and the pod is deleted. If the Job fails to complete successfully, it will be restarted according to the restartPolicy. The number of successful and failed Jobs to keep in the history is controlled by the successfulJobsHistoryLimit and failedJobsHistoryLimit fields, respectively.
view the status of a CronJob, you can use the kubectl get cronjobs command:
kubectl get cronjobs

Thank you for reading this blog🙏
I hope it helps 💕
— Safia Khatoon
Happy Learning 😊